

지난주와 지지난주 자료 구조 공부를 했었고 복습겸 정리해보려 한다.
사실 할게 많아 계속 미뤘는데 이런 상태가 계속 반복되고 있어 드디어 정리 해보려 글을 쓴다.
굉장히 긴 글이 될것 같은데 함께 힘내보도록하자.

그래서 먼저 자료구조는 왜 공부해야하는지 알고 시작을 해야하는데..

사실 처음에 배웠을 때 알았는데 지금은 까먹었기 때문에 다시 알아봤다.
💡 메모리를 효율적으로 사용해 데이터를 빠르고 안전하게 처리하자!
이게 자료구조의 궁극적인 목표다.
즉, 우리는 특정 상황(문제)에서 가장 짧은 시간에 효율적인 메모리 사용을 할 수 있는 자료구조를 잘 선택할 수 있도록 잘 배워놔야한다.
그러려면 우리는 가장 먼저 시간복잡도를 알아야한다.
시간복잡도란 무엇이고 왜 알아야할까?
시간 복잡도는 우리가 위에서 말한 짧은 시간을 판단하기 위한 척도가 된다.
공간 복잡도라고 작성한 프로그램이 얼마나 많은 메모리를 차지하는지 분석하는 방법도 있는데 요즘컴퓨터 성능이 워낙 좋아서 중요도가 떨어지기 때문에 설명은 안한다. 어차피 나중에 작성할 알고리즘은 다 시간 복잡도 중심이다.
우리는 시간 복잡도를 빅오 표기법을 사용해서 표현하는데 말 그대로 큰 O를 사용해 입력 범위 n을 기준으로 로직이 몇번 반복되는지 나타낸다.
예를 들면 아래의 코드의 경우 n번 로직이 반복된다. 그렇기 때문에 O(n)으로 표현할 수 있다.
for(let i = 0; i < n; i++){
console.log(i);
}
수학을 잘 배웠다면 그래프를 잘 읽을 수 있을것이다.
그래프마다 커지는 속도가 다른데 n이 아주 작을때를 제외하고는 시간 복잡도 순서는 위의 사진과 같다.
우리가 알아볼 자료 구조들은 평균적으로는 아래의 표와 같은 시간 복잡도를 가지고 최악의 경우 그 아래의 표와 같은 시간 복잡도를 가진다.
<자료 구조의 평균 시간 복잡도>
자료 구조접근탐색삽입삭제
| 배열 | O(1) | O(n) | O(n) | O(n) |
| 스택 | O(n) | O(n) | O(1) | O(1) |
| 큐 | O(n) | O(n) | O(1) | O(1) |
| 이중 연결 리스트 | O(n) | O(n) | O(1) | O(1) |
| 해시 테이블 | O(1) | O(1) | O(1) | O(1) |
| 이진 탐색 트리 | O(logn) | O(logn) | O(logn) | O(logn) |
| AVL 트리 | O(logn) | O(logn) | O(logn) | O(logn) |
| 레드 블랙 트리 | O(logn) | O(logn) | O(logn) | O(logn) |
<자료 구조의 최대 시간 복잡도>
자료 구조접근탐색삽입삭제
| 배열 | O(1) | O(n) | O(n) | O(n) |
| 스택 | O(n) | O(n) | O(1) | O(1) |
| 큐 | O(n) | O(n) | O(1) | O(1) |
| 이중 연결 리스트 | O(n) | O(n) | O(1) | O(1) |
| 해시 테이블 | O(n) | O(n) | O(n) | O(n) |
| 이진 탐색 트리 | O(n) | O(n) | O(n) | O(n) |
| AVL 트리 | O(logn) | O(logn) | O(logn) | O(logn) |
| 레드 블랙 트리 | O(logn) | O(logn) | O(logn) | O(logn) |
혹시라도 자료구조 성능을 측정 하고싶다면 아래의 코드를 사용해보자.
const start = new Date().getTime(); //작업이 시작되는 부분에 입력 //... const end = new Date().getTime(); //모든 작업이 끝나는 곳에 입력 console.log(end-start);
이제 설명을 하기 위한 기초작업을 마쳤으니 다음 단계로 넘어가보자.
자료구조의 종류
자료구조는 크게 선형, 비선형 구조로 나뉜다.
선형 구조
- 한 원소 뒤에 하나의 원소만 존재
- 자료들이 선형으로 나열됨
- 배열, 연결리스트, 스택, 큐, 해시

비선형 구조
- 한 원소 뒤 여러개의 원소 존재 가능(원소 간 다대다 관계)
- 계층적 구조, 망형 구조
- 그래프, 트리, 힙, 트라이

선형 구조
배열
가장 많이 사용해봤을 자료구조이다. (나는 그랬다)
- 원하는 원소의 index를 알고 있다면 O(1)로 원소를 찾을 수 있다.
- 원소를 삭제하게 되면 해당 index에 빈자리가 생긴다.
생성하는 방법
//빈 Array 생성
let arr1 = [];
//미리 초기화 된 Array 생성
let arr2 = [1,2,3,4,5];
let arr3 = Array(10).fill(0);
let arr4 = Array.from({length: 100},(_,i) => i); //0~99까지 [0,1,2 ...,99]추가, 삭제
const arr = [1,2,3];
arr.push(4); // [1,2,3,4] O(1)
arr.push(5,6); //[1,2,3,4,5,6] O(1)
//선형 시간 소요
arr.splice(3,0,128); // [1,2,3,128,4,5,6] O(n) 추가
arr.splice(3,1); // [1,2,3,4,5,6] O(n) 삭제연결 리스트 (Linked List)
- 각 요소를 포인터로 연결해 관리
- 각 요소는 노드라 부르며 데이터 영역, 포인터 영역으로 구성
- 메모리가 허용하는 한 요소 제한없이 추가 가능
- 탐색 O(n), 추가 O(1), 제거 O(1) 소요
- Singly Linked List, Doubly Linked List, Circular Linked List 존재

차이점배열연결 리스트
| 메모리 | 순차적 | 퍼져있음 |
연결리스트는 이럴때 사용하길 추천한다!
✅ 추가와 삭제가 반복되는 로직
Singly Linked List(단일 연결 리스트)
- Head에서 Tail까지 단방향으로 이어짐
- 가장 단순한 형태인 연결 리스트
- Tail은 Null로 끝을 의미 (연결이 끝남)

요소 찾기
‘4’를 찾는다면?
헤드 포인터부터 다음요소, 일치하지 않는다면 또 다음요소로 넘어감. O(n)
요소 추가
‘3’을 중간에 추가한다면?
포인터 영역을 다음 데이터 영역을 가리킴, 추가할 영역의 데이터 영역을 그 전의 포인터 영역과 연결. O(1)
주의: 데이터 추가할 곳의 탐색 과정이 추가되면 O(n)이 추가됨
요소 삭제
‘2’를 삭제한다면?
2의 데이터 영역을 가리키는 그 전의 포인터 영역을 2의 포인터 영역이 가리키는 데이터 영역과 연결해줌. O(1)
Doubly Linked List(양방향 연결 리스트)
- Singly Linked List보다 자료구조의 크기가 조금 더 큼

요소 추가
‘3’을 중간에 추가한다면?
(단일 연결 리스트와 비슷 & 이전 노드 만 추가 됨) O(1)
요소 삭제
‘2’를 중간에 삭제한다면?
(역시 단일 연결 리스트와 비슷 & 이전 노드 만 삭제 됨) O(1)
Circular Linked List(환형 연결 리스트)
- Singly 혹은 Doubly Linked List에서 Tail이 Head로 연결되는 연결 리스트
- 메모리 절약 가능
- 원형 큐등을 만들 때 사용

스택
- Last in First out (LIFO)
-> 마치 프링글스와 같다. (위에 쌓여있는 감자칩 먼저 먹을 수 있음) - Array의 push(), pop()으로 표현 가능
- 연결 리스트로도 표현 가능

큐
- First In First Out 의 선형구조 (FIFO) - DeQueue(unshift), EnQueue(push)
- Linear Queue, Circular Queue가 존재
-> 대기 줄과 같음 (먼저 온 사람 먼저 처리)
선형 큐
- Array로 표현 가능 - 하지만 DeQueue되어 빈 공간을 없애기 위해 앞으로 배열을 정렬하면 선형 시간이 필요 (낭비)
- Linked List 로 표현하게 되면 index 고민 하지 않아도 됨!
환형 큐
- 연결 리스트로 구현해도 크게 이점은 없음..
- 범위를 벗어나면 0부터 다시 입력되도록 하기
- 하지만 잘 사용은 안함.
해시 테이블
- key와 value를 받아 key를 해싱해서 나온 index에 값을 저장
-> 출석부처럼 이름-학번 방식 - 삽입 O(1), key를 알고 있다면 삭제, 탐색 O(1)
해시 함수
- 입력받은 값을 특정 범위 내 숫자로 변경하는 함수
function Hash(key){
...
return ~~;
};
Hash("gender"); //17261627361
Hash("name"); //12454525
Hash("age"); //57378 해시 테이블의 문제점
❗ 해시 충돌이 날 수 있다 ❗
그렇기 때문에 충돌을 해결하려는 방법이 세가지 있다.
✅ 선형 탐사법
- 충돌이 발생하면 옆으로 한칸 이동
- 최악의 경우 탐색에 선형 시간이 걸림
✅ 제곱 탐사법 - 충돌이 발생하면 충돌이 발생한 횟수의 제곱만큼 옆으로 이동
✅ 이중 해싱 - 충돌이 발생하면 다른 해시 함수를 이용
function Hash(key){
...
return ~~;
};
function Hash2(key){
...
return ~~;
};
Hash("gender"); //17261627361
Hash("name"); //12454525
Hash("age"); //12454525 이미 존재함
Hash2(Hash("age")); //5435✅ 분리 연결법
- 버킷의 값을 연결 리스트로 사용해 충돌 발생 시 리스트에 값 추가
- 최악의 경우 특정 버킷이 무한으로 늘어날 수 있음
비선형 구조
그래프
- 정점과 정점 사이를 연결하는 간선으로 이루어진 비선형 자료구조
- 정점 집합과 간선 집합으로 표현 가능
- 지하철 노선도
- 페이지 랭크 알고리즘에 쓰인다.
-> 구글 검색 알고리즘 - 정점은 여러 개의 간선을 가질 수 있음
- 간선은 가중치를 가질 수 있음
- 사이클이 발생할 수 있음
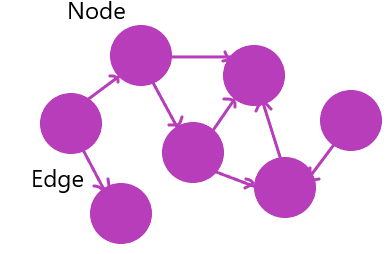
간선의 방향성
무방향 그래프
- 간선으로 이어진 정점끼리 양방향으로 이동 가능
- (A,B) 와 (B,A)는 같은 간선 취급
- 양방향 통행 도로

방향 그래프
- 간선에 방향성이 존재하는 그래프.
- 양방향으로 갈 수 있어도 <A,B>와 <B,A>는 다른 도로
간선의 연결 상태
연결 그래프
- 모든 정점이 서로 이동 가능한 상태

비연결 그래프
- 특정 정점쌍 사이에 간선이 존재하지 않음

완전 그래프
- 모든 정점끼리 연결된 상태
- 한 정점의 간선 수 = 모든 정점 - 1
- 모든 간선 수 = 모든 정점 -1 * 정점의 수

사이클
- 그래프의 정점과 간선의 부분 집합에서 순환이 되는 부분

트리
- 방향 그래프의 일종으로 정점을 가리키는 간선이 하나 밖에 없음
ex. 조직도, 디렉토리 구조 - 루트 정점을 제외한 모든 정점은 반드시 하나의 부모 정점을 가짐
- 정점이 n개인 트리는 반드시 n-1개의 간선을 가짐
- 루트에서 특정 정점으로 가는 경로는 유일
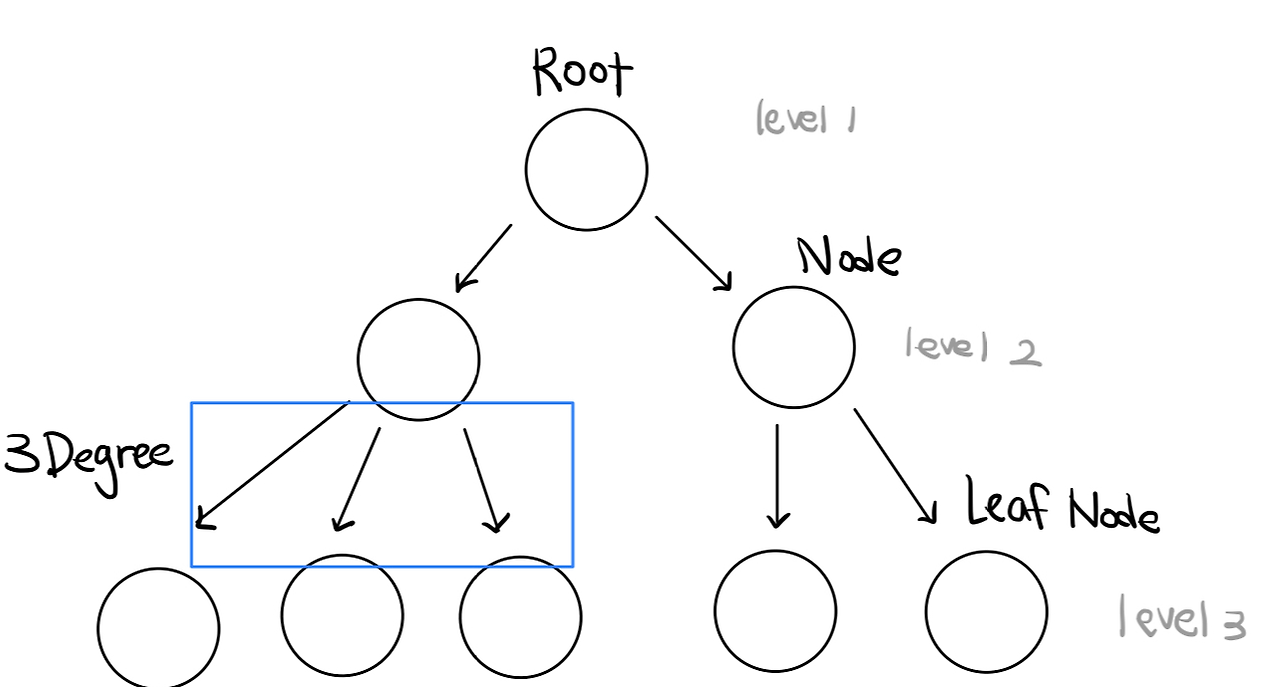
이진 트리
- 각 정점이 최대 2개의 자식을 가지는 트리
- 정점이 n개인 이진 트리는 최악의 경우 높이가 n
- 정점이 n개인 포화 또는 완전 이진 트리의 높이는 logN
- 높이가 h인 포화 이진트리는 2^h-1개의 정점을 가짐
- 이진트리가 응용되는 경우
- 이진 탐색 트리
- 힙
- AVL트리
- 레드 블랙 트리
완전 이진 트리
- 마지막 레벨을 제외하고 모든 정점이 채워져 있는 트리
포화 이진 트리
- 마지막 레벨도 모두 채워져 있는 트리
편향 트리
- 한 방향으로만 정점이 채워져 있는 트리

AVL 트리
- 최악의 경우 선형적인 트리가 되는 것을 방지하고 스스로 균형 잡는 이진 탐색 트리
- 두 자식 서브트리의 높이는 항상 최대 1만큼 차이남
- 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)
- 삽입, 삭제 할 때마다 균형이 안맞는것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전 시키며 균형 잡음
레드 블랙 트리
- 균형 이진 탐색 트리
- 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)
- "모든 리프 노드와 루트 노드는 블랙이고 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다"라는 규칙을 기반으로 균형잡음
트리 구현 방법
- 인접 행렬, 인접 리스트

이진 트리 구현 방법
- 배열 혹은 요소에 링크가 2개 존재하는 연결 리스트로 구현 가능

힙
- 이진 트리 형태를 가지며 우선순위가 높은 요소가 먼저 나가기 위해 요소가 삽입, 삭제 될 때 바로 정렬됨
- 우선 순위 큐에 힙이 포함됨
- 우선순위 큐
- FIFO인 큐와 달리 우선순위가 높은 요소가 먼저 나감
- 자료구조 x, 단지 개념!
- 우선순위 큐
- 우선 순위가 높은 요소가 먼저 나감
- 루트가 가장 큰 값이 되는 최대 힙과 루트가 가장 작은 값이 되는 최소 힙이 있음
- JS에선 직접 구현해서 사용해야 함
힙 요소 추가 알고리즘
- 요소가 추가될 때 트리의 가장 마지막 정점에 위치
- 부모 정점보다 우선 순위가 높으면 부모 정점과 순서를 바꿈 (조건에 맞지 않을때 까지 계속 반복)
- 과정을 반복하면 가장 우선순위가 높은 정점이 루트가 됨
- 완전 이진 트리의 높이는 logN이라 힙의 요소 추가 알고리즘은 O(logN)

힙 요소 제거 알고리즘
- 요소 제거는 루트 정점만 가능
- 루트 정점이 제거된 후 가장 마지막 정점이 루트에 위치
- 루트 정점의 두 자식 정점 중 더 우선순위가 높은 정점과 바꿈
- 두 자식 정점이 우선순위가 더 낮을 때 까지 반복
- 완전 이진 트리의 높이는 logN이라 힙의 요소 제거 알고리즘은 O(logN)

트라이
- 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조

트라이의 특징
- 검색어 자동완성, 사전 찾기 등에 응용
- 문자열을 탐색할 때 단순하게 비교하는 것보다 효율적으로 찾을 수 있음
- 문자열 길이가 L일 때, 삽입은 O(L)만큼 걸림
- 각 정점이 자식에 대한 링크를 전부 가져 저장 공간을 많이 사용
트라이 구조
- 루트는 비어있음
- 각 링크는 추가될 문자를 키로 가짐
- 각 정점은 이전 정점의 값 + 간선의 키를 값으로 가짐
- 해시 테이블과 연결 리스트를 이용해 구현 가능

여기까지가 내가 공부했던 자료구조 전부이다.
잘 따라왔으면 좋겠다.

'코테 준비 > 알고리즘' 카테고리의 다른 글
| 에라토스테네스의 체 - 소수 빠르게 알아내기 (0) | 2024.08.05 |
|---|---|
| 전체 탐색 - 조합 전체 탐색 (비트 연산 이용) (0) | 2024.08.05 |
| 숫자의 표현 문제 (0) | 2024.08.05 |
| 약수 구하기 (0) | 2024.08.05 |
| 나머지 연산의 특징 (0) | 2024.08.05 |